Written by
Corentin Mrejen
This is Part 1 of our series on building agentic AI systems for quantitative analysis. In this article, we introduce the foundational concepts that distinguish agentic AI from standard large language models, and explain the technical components we've built to implement true agency. In the next article, we'll explore context-aware learning through vector databases and retrieval-augmented generation.
From Conversational AI to Agentic Systems
Large language models have transformed how we interact with data. You can ask GPT-4 about statistical concepts, request code generation, or get explanations of complex analyses. Yet these interactions remain fundamentally reactive and stateless. Modern LLMs can maintain context within conversations through large context windows and session memory, but they remain fundamentally reactive assistants. They cannot autonomously execute analyses, invoke analytical tools, observe results, or pursue multi-step objectives that span beyond a single conversation session.
This limitation becomes apparent in quantitative workflows. An actuary validating quarterly assumptions doesn't just need answers to isolated questions. They need a system that understands their validation workflow, remembers previous quarters' analyses, proactively identifies data quality issues, and executes the necessary statistical tests autonomously. A quant testing factor loading stability doesn't just need code suggestions. They need infrastructure that retrieves relevant historical analyses, determines appropriate rolling window parameters based on past work, and adapts its approach when intermediate results reveal regime shifts.
The gap between "answer questions" and "accomplish analytical objectives" is what separates standard LLMs from agentic AI systems. This article explains that distinction conceptually, then shows you the technical architecture we built to bridge it.
What Makes AI Truly Agentic?
In artificial intelligence research, the term agency describes systems that operate with purpose, independence, and adaptability. Where traditional AI follows predefined workflows (if condition A, execute function B), agentic systems exhibit characteristics that enable them to pursue objectives with genuine autonomy.
Academic literature identifies several core characteristics that define agentic behavior. We present these not as abstract theory, but as concrete capabilities we're implementing in production systems for quantitative analysis. Each characteristic addresses a specific limitation of standard LLM interactions.
Characteristic 1: Reasoning and Goal-Based Decision Making
The first distinguishing characteristic is iterative reasoning toward defined goals. Standard LLMs generate responses based on prompts but exhibit no sustained reasoning process. They cannot observe intermediate results, reflect on whether those results are sufficient, and autonomously decide whether to pursue additional analysis.
True agency requires systems that reason about what they observe and adapt their approach accordingly. When you ask "Analyze factor loadings for stability," an agentic system doesn't simply generate pandas code and execute it. Instead, it reasons through a multi-step process. First, it considers what information it needs. "To analyze stability, I must first understand the data structure, time coverage, and available factors." It executes analysis to gather that information. Observing the results (10 years of daily data, 5 equity factors), it reasons again. "This temporal span is sufficient for rolling window analysis. I should compute correlations across 60-day windows to detect stability changes." It performs this analysis. Observing the correlation matrices, it detects variance in specific periods and reasons further. "Correlation shifts suggest regime changes. I should identify breakpoints statistically." Only after this iterative reasoning process does it synthesize findings.
This capability transforms how quantitative work gets done. Rather than executing fixed analytical scripts, you specify high-level objectives and the system reasons through appropriate methodology autonomously.
Characteristic 2: Autonomy and Ability to Take Action
Reasoning alone is insufficient. The second characteristic is autonomy in tool selection and action execution. Standard LLMs can suggest what tools to use but cannot actually use them. They output text describing analysis; they cannot perform analysis.
Agentic systems bridge this gap by autonomously selecting and invoking analytical tools. When reasoning determines that rolling correlation analysis is appropriate, the agent doesn't just recommend it. It generates the necessary pandas code, executes it in a secure environment, retrieves results, and integrates those results into its reasoning process. When visualization would aid understanding, it autonomously invokes visualization tools. When additional data preprocessing is needed, it performs those operations without explicit instruction.
This autonomy is what enables genuinely hands-off analytical workflows. You specify objectives; the system determines methodology, selects tools, executes operations, and delivers results. For actuaries running quarterly validations or quants performing hypothesis tests at scale, this autonomy directly translates to throughput acceleration.
Characteristic 3: Context Awareness and Memory
The third characteristic, persistent context awareness and memory, represents the crucial next step in our implementation. True agency requires systems that remember previous interactions, learn from analytical patterns, and apply that learned context to new problems across sessions.
Imagine a system that knows you typically run 60-day rolling correlations for equity analysis. When you ask to "check factor stability," it defaults to that window without asking. It remembers that last quarter's claims data required specific exposure adjustments and proactively applies them this quarter. It recognizes that your organization's validation workflow always tests for trend before investigating distributions, and suggests that sequence automatically.
This context awareness will be implemented using vector databases for semantic storage of analytical patterns and retrieval-augmented generation (RAG) to inject relevant historical context into reasoning processes. Rather than treating each analysis session independently, the system will maintain a growing knowledge base of your analytical preferences, successful methodologies, and data characteristics. We'll explore this architecture in detail in Part 2 of this series.
Technical Architecture: Building Agency Step by Step
Understanding what makes AI agentic conceptually is valuable. Building it requires solving concrete technical challenges. This section explains the architecture we've implemented to deliver reasoning and autonomous action, the first two characteristics of agency.
Foundation: The Large Language Model
At the foundation of our system is a large language model (specifically, Azure OpenAI's GPT-4.1-mini deployment). The LLM serves multiple critical functions. First, it provides natural language understanding, interpreting analytical requests expressed in human language rather than formal query syntax. When you ask "test for regime shifts in Q3-Q4," the LLM understands you're requesting time-based segmentation analysis with statistical change point detection.
Second, the LLM enables code generation. Rather than relying on predefined analytical functions, the system dynamically generates pandas and scikit-learn code tailored to your specific question and data characteristics. This flexibility means the system can handle arbitrary analytical requests without requiring developers to anticipate every possible analysis type.
Third, and most importantly for agency, the LLM provides the reasoning engine. Through careful prompt engineering and architectural patterns we'll describe shortly, the LLM reasons about what information it needs, which tools to invoke, and how to interpret results. This reasoning capability is what enables goal-directed behavior rather than simple stimulus-response patterns.
However, the LLM alone is insufficient for agency. It can reason and generate text, but it cannot observe the results of actions, adapt based on those observations, or autonomously execute multi-step workflows. These capabilities require additional architectural components.
Component 1: The ReAct Pattern for Iterative Reasoning
The first architectural component we implemented is the ReAct pattern (Reasoning and Acting), which addresses the reasoning and goal-based decision-making characteristic of agency. ReAct structures LLM interactions as iterative cycles of thinking, acting, and observing until objectives are achieved.
How ReAct Works
Traditional LLM interactions follow a simple pattern: user provides input, model generates output, interaction ends. ReAct extends this into a loop. The model receives a query and available tools. It reasons about what to do next, generating explicit "thoughts" about its approach. Based on that reasoning, it decides to either act by invoking a tool or provide a final answer. If it acts, tool results become observations fed back into the model, which then reasons again about next steps.
Critically, tools remain available throughout this cycle. After observing results from one tool invocation, the model can decide to invoke additional tools, pursue alternative analytical approaches, or conclude that sufficient information exists to answer the original question. This iterative availability is what enables adaptive reasoning.
ReAct in Practice: A Concrete Example
Consider a realistic quantitative workflow. An equity analyst asks: "Identify the strongest risk factors in this portfolio." Here's how ReAct processes this request.
Iteration 1 (Reasoning): The LLM receives the query and available tools (metadata extraction, code execution, categorical analysis, visualization). It reasons: "To identify risk factors, I need to understand what data is available, what time period is covered, and whether the data includes both returns and factor exposures." It decides to act by invoking the metadata tool.
Iteration 1 (Observation): The metadata tool returns: dataset contains 50 assets, daily returns over 5 years, plus columns for market beta, size factor, and value factor exposures. The LLM observes this information.
Iteration 2 (Reasoning): Observing the available factors, the LLM reasons: "I have sufficient data for factor analysis. I should compute factor loadings and their statistical significance to determine which factors drive portfolio risk." It generates pandas code to perform this analysis and invokes the code execution tool.
Iteration 2 (Observation): The code executes successfully, returning factor loadings and t-statistics. Market beta shows loading of 0.71 (t=8.3), size factor 0.23 (t=2.1), value factor 0.09 (t=0.8).
Iteration 3 (Reasoning): Observing these results, the LLM reasons: "Market beta is the dominant factor with high statistical significance. However, I should check whether these loadings are stable over time or if they vary by period, which would indicate regime changes." It generates code to compute rolling factor loadings.
Iteration 3 (Observation): Rolling analysis reveals that size factor loading increased sharply in Q3 2023, shifting from 0.15 to 0.31.
Iteration 4 (Synthesis): Having gathered sufficient evidence, the LLM synthesizes: "Market beta is the strongest risk factor at 0.71, explaining the majority of portfolio variance. However, size factor exposure increased significantly in Q3 2023, suggesting a regime shift in portfolio composition or market dynamics that warrants investigation."
This multi-iteration process demonstrates genuine reasoning. The agent didn't follow a predetermined analytical script. It observed intermediate results, recognized patterns that suggested additional analysis, pursued that analysis autonomously, and synthesized comprehensive findings. This is adaptive intelligence rather than scripted execution.

Why This Matters for Quantitative Work
For actuaries and quants, ReAct's value emerges in complex workflows. When you ask a nuanced question like "Are our loss reserves adequate given recent claims patterns?" the system doesn't just run a single calculation. It reasons through what "adequacy" means statistically (perhaps confidence intervals or stress testing), determines what analyses support that assessment (trend analysis, distribution fitting, extreme value theory), executes those analyses in sequence, and synthesizes findings into actionable recommendations. The mechanical workflow execution happens automatically; you focus on interpreting results and making decisions.
Component 2: The Model Context Protocol for Autonomous Action
ReAct enables reasoning, but reasoning alone accomplishes nothing without the ability to act. The second architectural component, the Model Context Protocol (MCP), addresses the autonomy and action characteristic of agency. MCP is what allows our agent to execute analyses rather than merely suggesting them.
The Problem MCP Solves
Historically, connecting AI systems to analytical tools required custom integration for each tool. Want the agent to query a SQL database? Write a custom SQL adapter. Want it to execute pandas code? Write another adapter. Want it to generate visualizations? Yet another integration. Each tool required bespoke middleware, error handling, serialization logic, and security measures. This approach doesn't scale and creates tight coupling between agent logic and tool implementations.
MCP inverts this relationship through standardization. Rather than custom integrations, MCP defines a universal protocol that any tool can implement and any agent can consume. Tools expose capabilities through standard interfaces. Agents discover available tools, inspect their schemas, and invoke them using standard message formats. The agent code knows nothing about whether a tool is implemented in Python, runs locally or remotely, or accesses databases versus file systems. It simply sends properly formatted requests and receives structured responses.
MCP Architecture: Three Tiers
MCP establishes a clean separation into three architectural tiers. The Host is your application. In our case, the agent system running ReAct reasoning loops. The Server exposes analytical capabilities. We built a specialized pandas server that provides four tools: metadata extraction, pandas code execution, categorical analysis, and Chart.js visualization generation. The Client sits between them, using JSON-RPC protocol over standard input/output (stdio), establishing a lightweight communication channel.
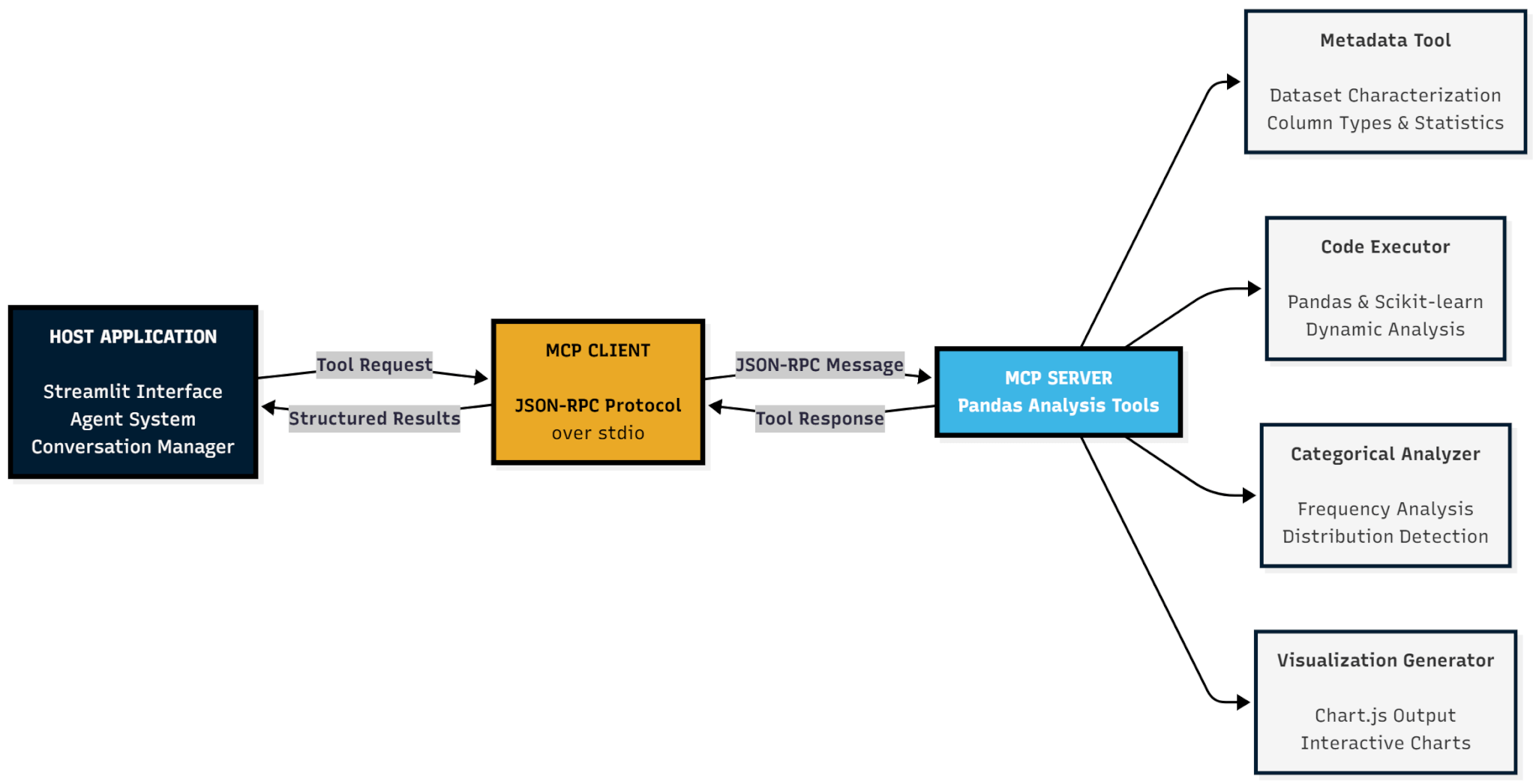
This separation provides several critical benefits. First, process isolation. The server runs as a separate operating system process with its own memory space. If generated code contains bugs or attempts unauthorized operations, only that isolated process is affected. The main application remains stable. Second, composability. Need SQL integration? Implement an MCP server for it; the agent can immediately use it without code changes. Need actuarial calculation libraries? Add another server. The agent discovers new tools automatically through MCP's tool listing mechanism. Third, security boundaries. Dangerous operations (like executing arbitrary code via Python's exec function) happen in controlled environments where resource limits, security scanning, and containment prevent abuse.
Our Pandas MCP Server: Safe Code Execution
The most powerful (and potentially dangerous) tool in our arsenal is dynamic code execution. When the ReAct reasoning loop determines that specific pandas operations are needed, it generates Python code as a string. That code must execute somehow. Simply running arbitrary code in the main application process would be catastrophically insecure. A bug or malicious input could crash the entire system or access sensitive data.
Our MCP server solves this through defense-in-depth security. The first layer is pattern-based scanning. Before execution, code is scanned for forbidden patterns: operating system access (os module, subprocess), file operations (open function, Path objects), code execution primitives (eval, exec within user code), network requests. Any violation triggers immediate rejection with detailed diagnostics.
The second layer is sandboxed execution. Code runs in a restricted namespace containing only pandas and numpy. No access to other libraries, no import capabilities beyond these sanctioned packages, no access to global state. Results must be explicitly assigned to a result variable, enforcing clear input-output contracts.
The third layer is subprocess isolation. The entire MCP server runs in a separate OS process. The operating system enforces memory limits, CPU quotas, and execution timeouts on this process independently of the main application. If code somehow bypasses earlier security layers and attempts malicious operations, the damage is contained within an isolated process that can be terminated forcefully.
These layers compound to create production-grade security. We can generate and execute arbitrary analytical code, enabling the flexibility that makes agentic behavior possible, without compromising system stability or data security.
Why MCP Is a Game Changer
The true power of MCP emerges in scalability and evolution. Traditional approaches require rebuilding integrations as your analytical toolkit grows. MCP-based systems simply add new servers as needed. Your organization acquires a specialized risk modeling library? Wrap it in an MCP server; the agent can use it immediately. You need integration with your actuarial systems? Implement the MCP protocol; instant availability.
This composability transforms how analytical infrastructure evolves. Rather than monolithic systems that ossify over time, you build modular infrastructure that grows organically with your organization's needs. The agent's reasoning capabilities remain constant; the tools it can leverage expand continuously. For enterprises with complex analytical ecosystems, this architectural approach provides genuine competitive advantage.
Moreover, MCP is becoming an industry standard. Anthropic introduced it, and adoption is growing across AI infrastructure providers. As more tools implement MCP servers, your agent automatically gains access to them without custom development. You're not building toward a proprietary standard; you're adopting infrastructure that will benefit from ecosystem growth.
What We've Built and What Comes Next
The architecture described above (LLM reasoning foundation, ReAct iterative reasoning pattern, and MCP autonomous tool execution) represents our current production implementation. This delivers the first two characteristics of agency: reasoning toward goals and autonomous action execution.
In practice, this means you can upload quarterly claims data or equity returns and ask complex analytical questions. "Test for regime shifts across the period." "Identify which product categories drive loss concentration." "Compute rolling VaR with appropriate window selection." The system reasons through methodology, executes analyses autonomously, adapts based on intermediate findings, and delivers comprehensive results. For actuaries running quarterly validations or quants executing hypothesis tests, this infrastructure measurably accelerates workflows.
However, we've only begun the journey toward full agency. The remaining characteristic, context awareness and memory, represents our next major implementation focus.
Part 2: Context-Aware Intelligence Through Vector Databases
The next article in this series will detail how we're implementing persistent context awareness. This involves semantic storage of analytical patterns using vector databases, retrieval-augmented generation to inject relevant historical context into reasoning, and mechanisms for the system to learn your specific analytical style. We'll show you the architecture supporting systems that remember you typically run 60-day rolling correlations, that your quarterly validation workflow follows specific sequences, and that your data exhibits particular seasonal patterns. This context transforms generic analytical infrastructure into genuinely personalized intelligent systems that understand not just what you're asking, but how you prefer to work and what approaches have proven successful in your specific context.
Building True Agency, Step by Step
This article established the conceptual foundation distinguishing agentic AI from standard LLM interactions. True agency requires three core characteristics: iterative reasoning toward goals, autonomous action execution, and persistent context awareness. We've implemented the first two through the ReAct pattern and Model Context Protocol, creating production systems that reason adaptively and act autonomously.
The technical details matter because they determine what's possible. ReAct isn't just an implementation choice. It's the architectural pattern that enables genuine goal-directed reasoning. MCP isn't just a protocol. It's the infrastructure that makes autonomous tool execution scalable and secure. These components work together to deliver systems that think and act rather than merely responding to prompts.
For quantitative professionals, the immediate value is clear: analytical workflows compress from hours to minutes. You specify objectives, and infrastructure handles execution. The longer-term value comes from systems that learn your patterns and continuously improve, making this genuinely transformative rather than incrementally better.
In the next article, we'll show you how context awareness and memory complete the picture. For now, understand this: we're building intelligence that thinks, acts, and remembers. That's what changes how quantitative work gets done.