Creating Highly Flexible, Configurable and Optimised Calculation Engines Using Abstract Syntax Trees
Financial institutions increasingly rely on complex models for portfolio valuation, risk assessment, and regulatory reporting. These rely on substantial calculation logic spread across vendor platforms, actuarial engines, data pipelines, and bespoke in-house models. Some systems are modern and modular; others are legacy environments shaped by years of incremental change. Regardless of their origins, organisations face familiar challenges: business logic becomes hard to trace, performance tweaks accumulate inconsistently, and even small adjustments can trigger unpredictable downstream effects. Transparency, validation, and long-term maintainability often suffer. Whilst this is never beneficial, it is especially cumbersome in regulated environments where clarity is essential.
At Risk at Work, we frequently support clients in improving or re-architecting these calculation-heavy processes. A consistent theme is the need to separate what the model should compute from how it is executed. This is where Abstract Syntax Trees (ASTs) prove highly effective. Originating in compiler design, ASTs provide a structured, language-agnostic way to represent formulas and business rules. When combined with the right architecture, implementation, and orchestration, they form a robust foundation for building engines that are transparent, testable, and adaptable.
By introducing ASTs into a modelling or reporting architecture, organisations can express business intent cleanly while keeping execution strategies flexible and interchangeable. This enables centralised optimisation, systematic validation, clearer governance, and the freedom to evolve underlying technology.
In the remainder of this article, we explore how ASTs can be used to build calculation engines that are more flexible, efficient, and robust. Through practical illustrations, we show how they simplify validation, reveal dependencies, support controlled extensions to the formula language, and help organisations balance performance with clarity.
Understanding ASTs: A Simple Illustration
Consider a common expression from cashflow modelling:
(net_premium + fee_income) * inflation_factor
At first glance, the calculation looks simple. But even a straightforward formula contains an underlying structure: an addition of net_premium and fee_income, followed by a multiplication with inflation_factor. An AST makes this structure explicit. When parsed, the expression becomes a tree where the root represents the multiplication, its left child represents the addition, and its right child represents the inflation factor:
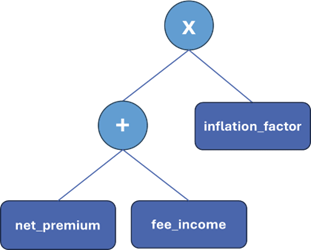
This tree captures far more information than the original formula. It clearly illustrates the hierarchy of operations and the relationships between components. This structured representation allows for precise analysis, validation, and optimisation, tasks that are difficult to achieve when the code is written out directly. Moreover, because ASTs are programming-language agnostic, the business logic they capture is independent of technical implementation choices.
From User Input to Optimised Execution
Once a user-provided formula is converted into an AST, the next step is to translate this tree into the target infrastructure. Conceptually, this translation mirrors the AST-construction process, but in reverse: each node in the tree is mapped to a corresponding construct in the execution environment.
The logic necessary to do so is implemented by the model developer. Because this logic is generic in nature, it can often be reused across applications or centralised in a shared repository for use across multiple models. A common approach is to use builder patterns, where each supported operation or object is mapped into the desired target infrastructure. The calculation engine then uses this builder to generate the final executable code.
For example, the AST for our earlier expression could be translated into Python code for the Polars package:
(pl.col("net_premium") + pl.col("fee_income")) * pl.col("inflation_factor")
For simple formulas, this translation may appear trivial. But in large financial models with hundreds of variables and thousands of operations, a centralised translation layer becomes extremely powerful. It guarantees that operations are executed consistently across the entire system. If the development team finds a more efficient way to express an operation, they only need to update the translation logic and every calculation automatically benefits, without requiring any changes from end users.
For instance, if using the + operator between pl.col() arguments turns out to be less efficient than calling a custom add_efficient method, the engine can be updated so that all + operations are translated accordingly. This can all be done without needing to make changes to the original user-provided formula.
(pl.col("net_premium").add_efficient(pl.col("fee_income"))) * pl.col("inflation_factor")
This architecture also greatly simplifies testing and optimisation. Alternative execution strategies, additional debugging output, or targeted performance improvements can all be introduced in a single location and applied automatically across the entire model.
The result is a system where business logic remains clean, declarative, and easy to understand, while performance considerations are handled centrally and consistently, ensuring efficiency throughout the model.
ASTs as a Foundation for Robust Validation
Because all calculations pass through the AST layer, validation becomes systematic and predictable. Unsupported operations can be flagged as soon as they appear. Missing variables can be identified before any execution takes place. Inconsistent or malformed expressions can be handled early with clear, actionable error messages for the user.
Consider the following expression:
projected_claim_cost = (expected_claims * severity) * inflation_factor
If severity has not been defined elsewhere in the configuration or is not available in the input, the AST makes this immediately detectable. Rather than encountering an obscure runtime error deep in the execution pipeline, the user receives a clear indication of what is missing.
In regulated environments and in large-scale models that may run for hours, this early validation is essential. The AST becomes the single point of truth where expressions are checked and normalised long before they reach the execution engine.
Understanding Dependencies: A Concrete Example
Another powerful benefit of using ASTs is the ability to extract the entire dependency network of a model automatically. Even modest financial models can become difficult to follow as the number of variables grow.
Consider the following formulas:
net_cashflow = premium_income - claim_outgo
premium_income = written_premium * earning_pattern
claim_outgo = reported_claims + ibnr
ibnr = exposure * loss_ratio * development_factor
Although the relationships are clear individually, they quickly become complex when combined with many others. By analysing the ASTs, the engine can determine the full dependency structure:
net_cashflow depends on premium_income and claim_outgopremium_income depends on written_premium and earning_patternclaim_outgo depends on reported_claims and ibnribnr depends on exposure, loss_ratio and development_factor
A high-level depiction might look like:
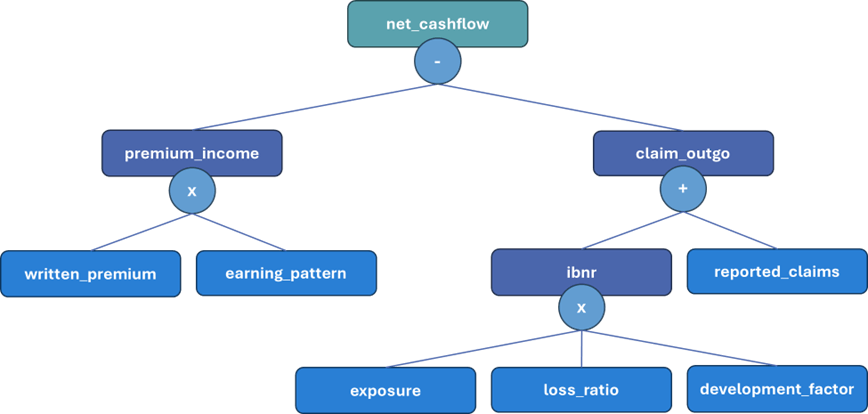
These tree decompositions allow the engine to automatically order calculations, detect circular references and ensure that all required inputs are available.
Furthermore, the ability to automatically generate these dependency trees gives analysts, domain experts, auditors, and model validators a clear view of how each value is derived and the logic behind it without needing to refer to or understand the internals of the engine.
Extending the Formula Language
Once formulas are expressed through ASTs, extending the available language features becomes both controlled and elegant. Domain-specific constructs can be introduced without compromising structure, safety or clarity. Consider examples such as:
(cashflow_table[premiums] + assumptions_table[premium_correction]) * constants[tax_rate]
quadratic_sum(pca1, pca2, pca3)
cashflows_bop[t] * discount_factors[t - 1]
These patterns are common in financial modelling, yet they fall outside what standard AST parsers, such as Python’s ast module, can interpret directly. To support them safely, the engine can introduce a preprocessing layer that identifies such constructs using, for example, regular expressions or lightweight tokenisation, and extracts the relevant metadata, such as table references or time indices.
Once this additional information is captured, the expression can be mapped into a corresponding AST structure where each component is represented explicitly. From there, the engine interprets the expression in a controlled manner by validating references, checking types, translating operations into the appropriate execution backend and applying any available optimisations.
The result is a formula language that grows in expressiveness without becoming fragile. Users can work with intuitive financial expressions, while the engine manages the complexity of interpretation, execution and optimisation behind the scenes.
Separation of Concerns and Future-Proof Architecture
Perhaps the greatest architectural benefit of using ASTs is the clean separation between business intent and implementation details. Business logic sits in a clear configuration layer, while the engine is responsible for how to compute it.
This separation makes the system easier to maintain and significantly reduces the risk of errors introduced through technical changes. It also ensures long-term stability. If an organisation moves from Polars to Pandas or from Python to a different environment entirely, the business logic does not need to be rewritten. Only the translation layer must evolve.
Furthermore, AST-driven engines integrate smoothly with traditional software. For cases where formula expressions which get translated by means of an AST are insufficient or impractical, developers can incorporate standard procedural code alongside formula-defined logic. The resulting architecture is not restrictive; it is enabling and allows the two to work side by side naturally, giving developers the flexibility to utilise whichever is most effective for the task at hand.
For financial organisations whose models may remain operational for a decade or longer, this flexibility is essential. It reduces technical debt, improves transparency and ensures that models remain auditable, resilient and ready for future developments.
A Practical Case Study
Risk at Work recently applied this approach while restructuring a complex cashflow model for a large Dutch insurer. The existing implementation had become difficult to modify due to a mixture of business logic and performance-driven technical code woven throughout the model. Changes in one part of the system often required substantial adjustments elsewhere, and introducing new optimisations was time consuming and error prone.
By placing all business logic into a clear configuration layer and rebuilding the execution around ASTs and the Polars package, the model became far cleaner, easier to maintain and significantly faster. Runtime improved by more than ninety five percent. Just as importantly, domain experts could now understand and modify the logic without needing to navigate layers of technical detail. The result was not only a faster system but also a more transparent, robust and future proof one.
Conclusion
Abstract Syntax Trees offer a sophisticated yet accessible foundation for building modern calculation engines. By translating formulas into structured representations, ASTs make it possible to validate, analyse, optimise and execute complex models with a level of flexibility that traditional approaches struggle to provide. They provide a clean separation between business intent and technical execution, allow dependency structures to emerge naturally, and they make powerful domain specific enhancements possible without compromising integrity or performance.
As the complexity of enterprise modelling continues to grow, organisations must rethink how they structure and manage their calculation logic. AST based architectures offer a path towards systems that are both rigorously engineered and easily adaptable. For teams that find themselves limited by rigid code structures, slow calculations or models that are difficult to understand, ASTs provide a compelling alternative that brings clarity, performance and long term resilience.
It is worth taking a moment to reflect on where modelling challenges truly originate: from the business logic itself, or from the way that logic is embedded in code. Recognising that distinction is often the turning point. Once business rules are expressed abstractly rather than entangled with implementation, the architecture becomes free to evolve. Models scale more gracefully, stakeholders gain transparency and organisations are better positioned to meet the increasingly demanding expectations of modern financial modelling.
Written by Floris ten Lohuis. For questions, further insights, or to explore practical applications of these ideas, feel free to get in touch at floris@riskatwork.nl